NVIDIA lauches next-gen HGX with B300 GPUs
NVIDIA HGX B300 Server
The NVIDIA HGX B300 is the most advanced server platform engineered to power the next wave of AI and high-performance computing breakthroughs to date.
Based on the Blackwell Ultra architecture, this platform sets a new benchmark in scale, performance, and memory bandwidth for massive AI workloads, large language model (LLM) inference, and real-time simulation.
Why Choose HGX B300?
The HGX B300 is purpose-built for enterprises and research institutions needing massive compute capabilities. From LLMs with hundreds of billions of parameters to real-time AI inference across multimodal tasks, this platform offers:
- Double the memory and GPU interconnect bandwidth over HGX B200
- Massive parallelism for faster time-to-results in AI/ML workflows
- Energy efficiency optimized through 5th-gen NVLink and advanced thermal control
- Futureproof AI infrastructure, ready for GPT-5+ and beyond
 Courtesy of NVIDIA.
Courtesy of NVIDIA.

Godì 1.8E2D-NV8
8U 19"
The excellence of AI Supercomputing Platform based
on Intel® Xeon® 6th generation and 8 NVIDIA B300 SXM6 !
Top applications
Scientific simulation & digital twins
AI/ML model training & LLM inference
Cybersecurity & real-time data analysis
HGX B300 vs HGX B200: comparison
Feature | HGX B300 | HGX B200 |
Form Factor | 8x NVIDIA Blackwell Ultra SXM | 8x NVIDIA Blackwell SXM |
FP4 Tensor Core | 144 PFLOPS | 105 PFLOPS | 144 PFLOPS | 72 PFLOPS |
FP8/FP6 Tensor Core | 72 PFLOPS | 72 PFLOPS |
INT8 Tensor Core | 2 POPS | 72 PFLOPS |
FP16/BF16 Tensor Core | 36 PFLOPS | 36 PFLOPS |
TF32 Tensor Core | 18 PFLOPS | 18 PFLOPS |
FP32 | 600 TFLOPS | 600 TFLOPS |
FP64/FP64 Tensor Core | 10 TFLOPS | 296 TFLOPS |
Total Memory | Up to 2.3 TB | 1.4 TB |
NVLink | Fifth generation | Fifth generation |
NVIDIA NVSwitch™ | NVLink 5 Switch | NVLink 5 Switch |
NVSwitch GPU-to-GPU Bandwidth | 1.8 TB/s | 1.8 TB/s |
Total NVLink Bandwidth | 14.4 TB/s | 14.4 TB/s |
Networking Bandwidth | 1.6 TB/s | 0.8 TB/s |
Attention Performance | 2X | 1X |
HGX B300 vs HGX H100: comparison
AI Reasoning Inference
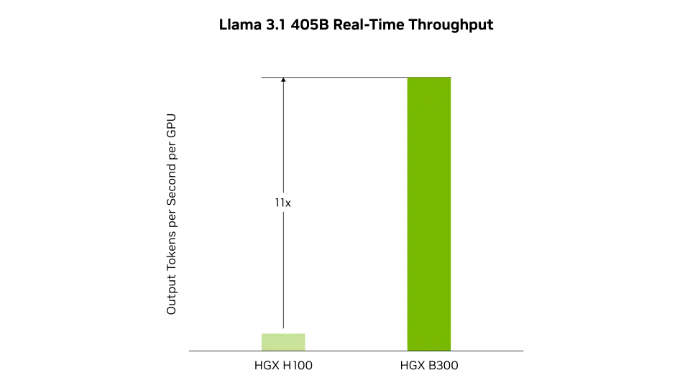
Courtesy of NVIDIA.
HGX B300 achieves up to 11x higher inference performance over the previous H100 generation for models such as Llama 3.1 405B.
AI Training
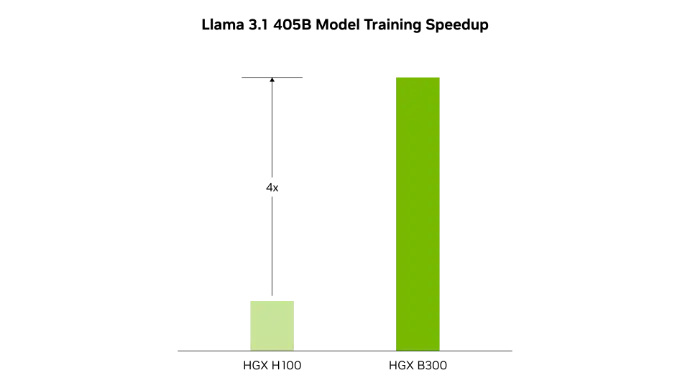 Courtesy of NVIDIA.
Courtesy of NVIDIA.The second-generation Transformer Engine, featuring 8-bit floating point (FP8) and new precisions, enables a remarkable 4x faster training for large language models like Llama 3.1 405B.
Interested? Get in touch with our sales team! We have servers and configurations available now.
2CRSi is NVIDIA Elite Partner.
![]()