NVIDIA lance la nouvelle génération de HGX avec des GPU B300
Serveur NVIDIA HGX B300
Le serveur NVIDIA HGX B300 est la plateforme la plus avancée jamais conçue pour propulser la prochaine vague d’innovations en intelligence artificielle et en calcul haute performance.
Basée sur l’architecture Blackwell Ultra, cette plateforme établit une nouvelle référence en matière de performance et de bande passante mémoire pour les charges de travail IA, l’inférence de grands modèles de langage (LLM) et la simulation en temps réel.
Pourquoi choisir le serveur HGX B300 ?
Le HGX B300 est spécialement conçu pour les entreprises et les institutions de recherche ayant besoin de capacités de calcul importantes. Des modèles de langage comptant des centaines de milliards de paramètres ou d’inférence en temps réel sur des tâches multimodales, cette plateforme offre :
- Une mémoire et une bande passante d’interconnexion GPU doublées par rapport au HGX B200
- Un parallélisme pour des résultats plus rapides dans les workflows d’IA et d’apprentissage automatique (ML)
- Une efficacité énergétique optimisée grâce à la 5e génération de NVLink et à un contrôle thermique avancé
- Une infrastructure IA pérenne, prête pour GPT-5+ et les générations suivantes
 Image venant de NVIDIA.
Image venant de NVIDIA.

Godì 1.8E2D-NV8
8U 19"
L'excellence de la plateforme de supercalcul IA basée sur Intel® Xeon® 6e génération et 8 NVIDIA B300 SXM6 !
Applications phares
Simulation scientifique & jumeaux numériques
Entraînement de modèles IA/ML & inférence de LLM
Cybersécurité & analyse de données en temps réel
HGX B300 vs HGX B200 : comparaison
Feature | HGX B300 | HGX B200 |
Form Factor | 8x NVIDIA Blackwell Ultra SXM | 8x NVIDIA Blackwell SXM |
FP4 Tensor Core | 144 PFLOPS | 105 PFLOPS | 144 PFLOPS | 72 PFLOPS |
FP8/FP6 Tensor Core | 72 PFLOPS | 72 PFLOPS |
INT8 Tensor Core | 2 POPS | 72 PFLOPS |
FP16/BF16 Tensor Core | 36 PFLOPS | 36 PFLOPS |
TF32 Tensor Core | 18 PFLOPS | 18 PFLOPS |
FP32 | 600 TFLOPS | 600 TFLOPS |
FP64/FP64 Tensor Core | 10 TFLOPS | 296 TFLOPS |
Total Memory | Up to 2.3 TB | 1.4 TB |
NVLink | Fifth generation | Fifth generation |
NVIDIA NVSwitch™ | NVLink 5 Switch | NVLink 5 Switch |
NVSwitch GPU-to-GPU Bandwidth | 1.8 TB/s | 1.8 TB/s |
Total NVLink Bandwidth | 14.4 TB/s | 14.4 TB/s |
Networking Bandwidth | 1.6 TB/s | 0.8 TB/s |
Attention Performance | 2X | 1X |
HGX B300 vs HGX H100 : comparaison
Inférence raisonnée en IA
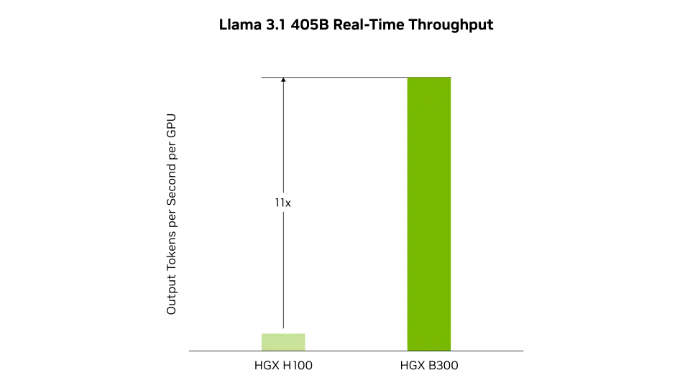
Image venant de NVIDIA.
Le HGX B300 offre jusqu’à 11 fois plus de performance en inférence par rapport à la génération précédente H100, pour des modèles tels que Llama 3.1 405B.
Entraînement de l’IA
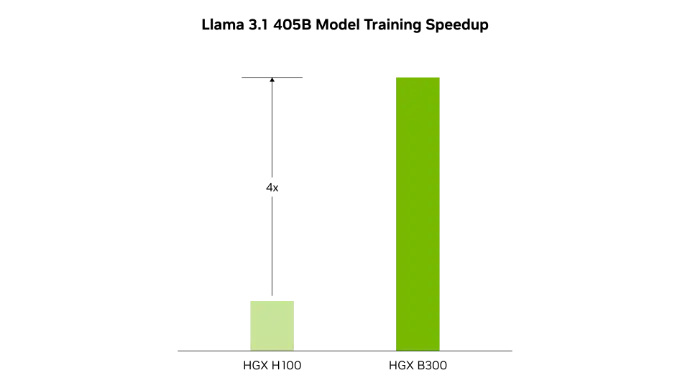 Image venant de NVIDIA.
Image venant de NVIDIA.
La deuxième génération du moteur Transformer, dotée du format flottant 8 bits (FP8) et de nouvelles précisions, permet un entraînement jusqu’à 4 fois plus rapide des grands modèles de langage comme Llama 3.1 405B.
Intéressé ? Contactez notre équipe de vente ! Nous avons des serveurs et des configurations disponibles dès maintenant.
2CRSi est un partenaire Elite de NVIDIA.
![]()